Background on Text-to-Image Systems
This section will cover theory behind how text-to-image (T2I) models work including an overview of diffusion systems. It will also describe how prompts are designed and how to think about their mechanics in the context of inputs to downstream text-to-image systems. We will cover the basics of what is going on in some of your favorite T2I functionalities including upscaling, outpainting, and image-to-image transformations.
This section is intended to give enough insight into what's going on under-the-hood of any text-to-image system so that you have more intuition for what certain parameters and ways of interacting with these models actually do.
Given the theoretical nature of this section, it is optional, though we do highly recommend at least skimming it so you become a more well-rounded prompting practitioner.
Basics of Image Diffusion Models
While T2I systems have been around for quite a while, in the last 1-2 years a new class of incredibly powerful image generators has emerged which includes models such as Stable Diffusion, Midjourney, and Dall-E 2. Although the full details of some of these systems is not public, they are almost certainly built on a variation of denoising diffusion models (or just diffusion models for short).
Originally introduced in seminal work from Stanford, these diffusion models run a sophisticated process of converting a noisy image into a high-quality image based on the guidance of a text prompt. The basic flow looks like this:

Let's now discover what's going on under-the-hood of the Diffusion Model.
A T2I diffusion model has three main modules all of which are trained neural networks:
- Text Encoder
- Diffuser
- Image Encoder/Decoder
Text Encoder
The text encoder module takes our input prompt and converts it into a numerical representation of the words in our prompt that the rest of the model can operate on. Each word in the prompt becomes a numerical vector called an embedding, and the goal of the text encoder is to ensure that each embedding captures the semantics of its corresponding word in a way that the rest of the model could eventually extrapolate an image from that embedding.
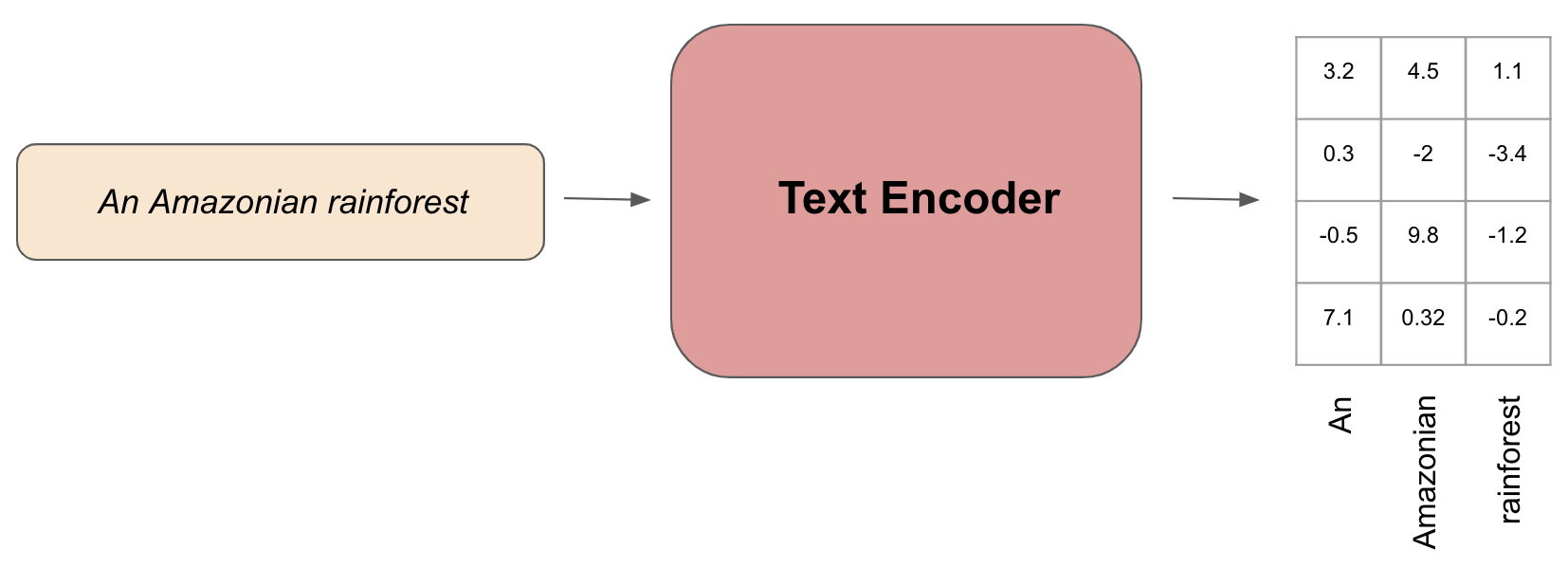
The text encoder should learn that the embedding for cat roughly translates to something that an image generator could associate with a cat picture. The encoder is trained from data so that it can produce these semantically rich embeddings.
Advanced Details
The text encoder is typically a transformer-based language model called CLIPText. This model was trained on a dataset of 400M image-caption pairs crawled from the web. The model consists of a text encoder and an image encoder where the two encoders are trained to produce embeddings that are close to each other according to a metric called cosine similarity. Once this training is done, our diffusion model just uses the text encoder portion of CLIP.
Diffuser
The diffuser module does most of the heavy lifting associated with what we call diffusion.
At its core, the diffusion model takes an initial noisy image (and also the encoded text embeddings from the encoder) and through an iterative process gradually denoises the image of noise until it hopefully produces a desired image aligned with what the prompt is describing.
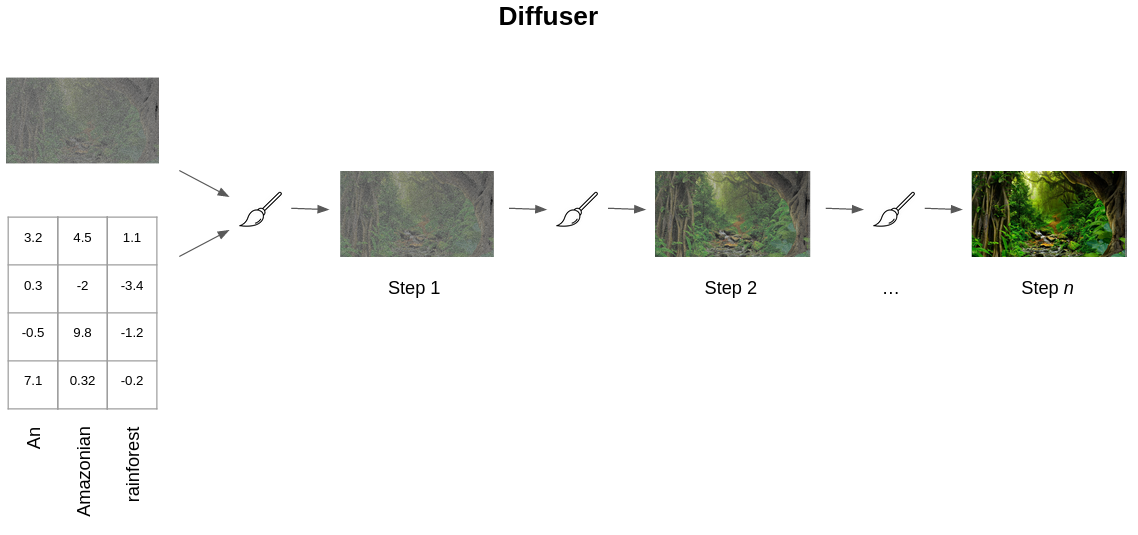
Advanced Details
A natural question to ask is how does the diffuser know to correctly denoise the image?
The diffuser is composed of a UNET neural network. The training data set for the UNET consists of a normal image that has had a tiny bit of noise added to it:

The UNET is then trained to take the slightly noisy image and output the amount of noise that had been added to it originally. The additional detail here is that diffusion systems are trained with a dataset of often millions of very aesthetically appealing images. As an example, the Laion Aesthetics that Stable Diffusion was trained on consisted of hundreds of millions of images scraped from webpages.
When we actually run our diffusion system, the UNET predicts a noise amount for a noisy input image which is then subtracted from the noisy image to get a less noisy image. This iterative process is then repeated for some number of steps. The number of UNET denoising steps is often a parameter tuned to achieve the best results. Because this denoising is a sequential process, it is hard to parallelize and thus can be quite slow.
For a neat visualization of how the denoising process looks and how an image starts to emerge check out this cool video from Jay Alammar.
Image Encoder/Decoder
The components that we've described so far would be perfectly sufficient to build a reasonable T2I system. The image encoder and decoder modules were added in this paper to speed up the image generation process.
The image encoder is used during the training process to effectively compress the matrix of image pixels into a smaller representation that the UNET can operate on. The image decoder is used during the generation process to take the output of the UNET and expand it back into a full image in a pixel format. This means that the denoising process is operating on what are called compressed latents.
Advanced Details
The image encoder and decoder are technically the branches of a neural network called an autoencoder which is trained to take an image, run it through an encoder to compress it, and then run it through a decoder to decompress back into an image in such a way that the decompressed image is as close as possible to the original image.
With these three components combined, we have the core backbone of the diffusion model that powers most state-of-the-art T2I systems today.

Now that we've described the foundations of diffusion systems, let's discuss some of the other functionalities you know and love when using image generation systems.
How does outpainting work?
Outpainting is a tool for taking an existing image and expanding it by filling in some blank canvas around it in a stylistically and visually consistent way. This ability was released in Midjourney 5.2 though they call it Zoom Out.

Outpainting is very related to another image generation capability called inpainting. In fact, outpainting can actually be implemented as inpainting over a blank canvas.
There are numerous techniques for performing inpainting as this is a standard problem in image generation. When it comes to using Stable Diffusion for inpainting, such a system uses a neural network (similar to the one described above) that was trained by randomly erasing parts of images and teaching the network to recover the missing areas conditioned on input text prompts.
How does upscaling work?
Upscaling is the process of increasing the size and resolution of an image by smoothly refining and improving the image quality as per this example.

In the case of the Stable Diffusion paper, upscaling is done via a similar model to what we described above. However, instead of only adding the embeddings of the text prompt to the diffuser module processing, we also add encoded embeddings of a low resolution image that we are trying to upscale. This combined concatenation process allows the model to learn how to improve the resolution of noisy images in a way that is consistent with the text prompt.
How does image-to-image generation work?
Image-to-image (img2img) generation is the process of transforming an existing image to a new image typically via a text-guided prompt.1 This is often used to perform image style transfer where the new image is guided via a stylistic prompt modifier. An example of this adapted from Meng et al. is shown below:

There are many techniques for performing img2img synthesis, though most of the state-of-the-art systems use a variant of the diffusion model above where we also feed in a noisy version of our starting image (in addition to the text prompt) to condition the denoising process of the diffuser module.
Some Midjourney Details
With those theoretical foundations in place, we can now discuss how some of these concepts play out in the context of interacting with the Midjourney system.
How do styles in prompts work?
When interacting with Midjourney, you are often able to create explicit styles by using carefully chosen words in your prompt as from TechHalla's prompt guide.

We can see how Midjourney is able to capture such diverse styles given the diffusion architecture we've learned about. By including explicit words in the prompts that are fed into the text encoder during the training process, the model learns to associate those words with certain styles. When we then invoke those words in our prompts, the text encoder produces embeddings that are associated with those styles. The diffuser module then uses those embeddings to guide the denoising process to produce an image that is consistent with the style we are trying to invoke.
How do negative prompts work?
You can provide negative prompts in Midjourney by adding the things you don't want to see after a --no block as in:
The details of how this works for diffusion models is that during the image denoising process in our diffuser component, when we perform one iteration of denoising we actually perform two distinct steps.
First, we denoise the noisy image conditioned on a text prompt we care about and second we denoise the noisy image without a text prompt. We then subtract this second image from the first. This process serves to bias the denoising even more toward the prompt we care about and away from random other generations.
Now, when we use a negative prompt, we are not using an empty prompt for that second denoised image that we subtract from the first but actually the negative prompt we provided. In this way, we bias the denoising process away from generations that could look like the negative prompt description. For more details check out this resource showing how this is implemented in code.
Test your knowledge
What are the three components of a diffusion image generation system?
How is the text encoder of a diffusion system implemented?
How does the diffuser component of a T2I system leverage the input text?
How are negative prompts implemented in Midjourney?
Get involved
Join us at X, with the hashtag #PromptingForArtists to share your results, questions, or comments. You can also tweet @techhalla or @mihail_eric.
References
To cite this content, please use:
@article{promptingforartists,
author = {Luis Riancho and Mihail Eric},
title = { Prompting for Artists - Text-to-Image Systems Theory},
howpublished = {\url{https://promptingforartists.storia.ai}},
year = {2023}
}
-
Technically inpainting/outpainting and upscaling also fall under the umbrella of image-to-image generation though here we are referring to stylized img2img generation. ↩